Spark Streaming 大规模流式数据处理的新贵
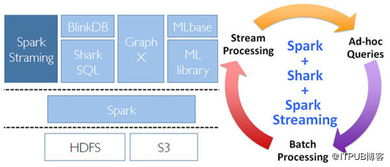
在大数据时代,实时数据处理的需求日益增长,传统批处理模式已难以满足高时效性场景。Apache Spark Streaming作为Apache Spark生态系统中的流式处理模块,凭借其高效、可扩展的特性,迅速崛起为大规模流式数据处理领域的新贵。
一、Spark Streaming的核心优势
Spark Streaming采用微批处理(Micro-Batch)架构,将实时数据流切割成一系列小批次(如每秒一批),并利用Spark引擎的批处理能力进行处理。这种设计不仅继承了Spark在批处理中的高性能与容错性,还实现了亚秒级的低延迟处理。其核心优势包括:
- 高吞吐量与低延迟:通过内存计算和RDD(弹性分布式数据集)优化,能同时处理数百万条数据流。
- 易用性与生态整合:支持Java、Scala、Python等多种语言,并可无缝集成Spark SQL、MLlib等组件,实现流批一体与实时机器学习。
- 容错与一致性:基于检查点(Checkpoint)机制保障数据精确一次(Exactly-Once)处理语义。
二、应对大规模流式数据的挑战
面对海量数据流,Spark Streaming通过分布式架构动态扩展计算资源。其窗口操作(如滑动窗口、滚动窗口)允许对时间范围内的数据进行聚合分析,适用于监控、风控等场景。与Kafka、Flume等消息队列的深度集成,进一步提升了数据摄入的稳定性。
三、实际应用场景
从互联网公司的实时用户行为分析,到金融领域的欺诈交易检测,再到物联网设备的数据监控,Spark Streaming已广泛应用于各行各业。例如,Netflix利用其处理每秒数TB的日志流,以优化视频推荐系统;Uber则依赖它实时计算交通流量与定价策略。
四、未来展望与挑战
尽管Spark Streaming在流处理领域占据重要地位,但仍面临实时性更高场景(如毫秒级延迟)的竞争,例如Apache Flink的直接流处理模型。随着Spark Structured Streaming的持续优化,其将更侧重于简化API并提升事件时间处理能力,以巩固其作为流式数据处理“新贵”的地位。
Spark Streaming以其强大的生态支持与平衡的性能表现,成为企业构建实时数据处理平台的关键选择,推动着大数据技术向实时化、智能化演进。
如若转载,请注明出处:http://www.antpainter.com/product/16.html
更新时间:2026-05-22 12:02:30