实时计算 流数据处理系统简析
随着大数据时代的深入发展,数据处理的需求已从传统的批量处理(Batch Processing)模式,逐渐扩展到对实时性要求极高的流式数据处理(Stream Processing)。实时计算,特别是流数据处理系统,已成为现代企业数据架构中不可或缺的核心组件,为即时决策、实时监控和动态交互提供了关键的技术支撑。
一、实时计算与流数据处理的定义与特点
实时计算通常指在数据产生后极短的时间内(如毫秒至秒级)完成数据的处理、分析并给出结果的计算模式。其核心目标是缩短数据从产生到产生价值的延迟,实现“数据驱动,即时响应”。
流数据处理是实时计算的一种典型实现范式,它处理的是无界数据流。与有界的、静态的批量数据集不同,数据流是连续、无序、无限且随时间快速到达的记录序列。例如,物联网传感器读数、在线交易日志、社交媒体动态、网络点击流等,都是典型的数据流来源。
流数据处理系统的主要特点包括:
- 低延迟:系统设计首要目标是处理延迟极低,能够近乎实时地输出结果。
- 高吞吐:能够持续处理海量、高速到达的数据。
- 容错性:在节点故障时,能保证计算状态的准确性和数据不丢失。
- 状态管理:支持对有状态的计算(如窗口聚合、模式匹配)进行高效管理。
- Exactly-Once语义:确保每条数据对最终结果的影响有且仅有一次,保证处理的精确性。
二、流数据处理系统的核心架构与概念
一个典型的流处理系统架构通常包含以下核心部分:
- 数据源(Source):持续产生数据流的源头,如消息队列(Kafka, Pulsar)、日志文件、传感器网络等。
- 流处理引擎(Processing Engine):系统的核心,负责执行用户定义的计算逻辑。它接收数据流,进行转换、聚合、分析等操作。
- 状态存储(State Storage):用于存储计算过程中的中间状态(如累加器、窗口内容),是实现复杂有状态计算的基础。
- 数据汇(Sink):处理结果的输出目的地,如数据库、仪表盘、消息系统或另一个流处理任务。
关键的计算模型概念包括:
- 窗口(Window):将无限流划分为有限的数据块进行处理,主要有时序窗口(滚动、滑动、会话)和计数窗口。
- 时间语义:
- 事件时间(Event Time):数据实际发生的时间。
- 处理时间(Processing Time):数据被系统处理的时间。处理事件时间乱序数据是流系统的关键挑战。
- 水印(Watermark):一种衡量事件时间进展的机制,用于推测数据流的完整性,触发窗口计算并处理延迟数据。
三、主流流处理系统简介
目前业界存在多种流处理系统,各有侧重:
- Apache Flink:以其统一的流批处理架构、精确的状态管理和强大的事件时间支持而闻名。它提供了高吞吐、低延迟且保证Exactly-Once语义的处理能力,是当前开源领域的领先者之一。
- Apache Kafka Streams:一个轻量级的客户端库,直接将Kafka主题作为输入输出流。它深度集成于Kafka生态,易于嵌入Java/Scala应用,适合构建微服务内的流处理应用。
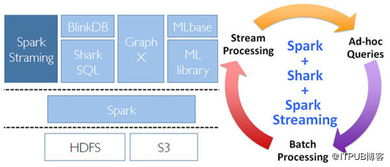
- Apache Spark Streaming:基于微批处理(Micro-Batch)模型,将流数据分解为一系列极小的批作业进行处理。它优势在于与Spark生态(SQL, MLlib)的无缝整合,适合已有Spark批处理栈且对延迟要求为秒级的场景。
- Apache Storm / Heron:早期的低延迟流处理系统,模型更为底层,延迟极低,但API相对原始,Exactly-Once语义支持较晚。
- 云厂商托管服务:如AWS Kinesis Data Analytics、Google Cloud Dataflow(基于Apache Beam模型)、Azure Stream Analytics等,提供了免运维、高可用的托管流处理服务。
四、应用场景与挑战
典型应用场景:
- 实时监控与告警:IT系统运维、业务指标(如交易额、点击率)实时监控。
- 实时推荐与个性化:根据用户实时行为动态调整推荐内容。
- 金融风控与欺诈检测:实时分析交易流,识别异常模式。
- 物联网数据分析:处理海量设备传感器数据,进行预测性维护。
- 实时数据仓库与ETL:将流数据实时清洗、转换并注入数仓,实现数据“新鲜度”最大化。
主要挑战:
1. 数据乱序与延迟:网络等因素导致数据到达顺序与发生顺序不一致,需要复杂的时间语义和水印机制应对。
2. 状态管理与容错:如何在分布式环境下高效、一致地管理状态,并在故障时快速恢复,是系统设计的难点。
3. 系统弹性与资源管理:如何根据数据流速动态调整计算资源,实现成本与性能的平衡。
4. 流批一体化:如何用同一套API和引擎无缝处理流和批数据,简化架构。
五、未来展望
流数据处理系统将继续向更低的延迟、更高的吞吐、更强的语义保证以及更简化的编程模型发展。与人工智能、机器学习的深度结合(如在线学习、实时模型推理)将成为重要方向。流批融合的架构(如Flink、Spark Structured Streaming倡导的)将成为标准,使得开发者能够以统一的视角处理所有数据。随着边缘计算的兴起,流处理能力也正在向网络边缘下沉,以实现更极致的实时响应。
实时计算与流数据处理系统是挖掘数据即时价值的关键利器。理解其核心原理、技术选型与适用场景,对于构建高效、敏捷的现代数据平台至关重要。
如若转载,请注明出处:http://www.antpainter.com/product/24.html
更新时间:2026-04-16 02:54:03